doris-spark-connector 源码编译

doris-spark-connector 源码编译
莫已诺doris-spark-connector 1.3.1 bug 处理记录
起因
业务需要Spark读写 Doris 数据库,使用官方提供的Spark Doris Connector
pom引用版本如下
1 | <properties> |
在读取Doris 中Date时间格式出现如下BUG
24/04/29 15:05:30 ERROR RowBatch: Read Doris Data failed because:
java.lang.IllegalArgumentException: Spark type is DATEV2, but arrow type is DATEDAY.
at com.google.common.base.Preconditions.checkArgument(Preconditions.java:125)
at org.apache.doris.spark.serialization.RowBatch.convertArrowToRowBatch(RowBatch.java:304)
at org.apache.doris.spark.serialization.RowBatch.(RowBatch.java:122)
at org.apache.doris.spark.rdd.ScalaValueReader.hasNext(ScalaValueReader.scala:210)
at org.apache.doris.spark.rdd.AbstractDorisRDDIterator.hasNext(AbstractDorisRDDIterator.scala:56)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:760)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$getByteArrayRdd$1(SparkPlan.scala:388)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:891)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2$adapted(RDD.scala:891)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:367)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:331)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:92)
at org.apache.spark.TaskContext.runTaskWithListeners(TaskContext.scala:161)
at org.apache.spark.scheduler.Task.run(Task.scala:139)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:554)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1529)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:557)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)

格式字段:
之前偷懒,把同为时间DateTime格式的birthday改成 varchar 来解决这个问题。
后面添加新字段 imp_data 用来动态分区,感觉这样偷懒不是办法麻烦就打算去处理这个BUG。
但是官方最新的maven包版本就是1.3.1 (24年1月份传入)。就去该可扩展的github下查看 doris-spark-connector
issues 的确有人提到这个问题,看源码已经处理了这个BUG。所以解决方法就是通过源码编译本地打包。
步骤
- 把Doris官方提供了编译环境的docker镜像 pull 下来
1 | docker pull apache/doris:build-env-ldb-toolchain-latest |
- run docker容器
1 | docker run -it --network=host \ |
其中 -v /e/Docker/APP/Doris/data/.m2:/root/.m2 是把maven 在容器中的本地仓库挂载出来
-v /e/Docker/APP/Doris/data/doris-branch-2.0:/root/doris-branch-2.0/ 是为了把需要编译的源码传入
- 从git clone 下最新的主干源码
1 | git clone https://github.com/apache/doris-spark-connector.git |
接下来就是进入容器执行build.sh
1
2cd /root/doris-branch-2.0/doris-spark-connector/spark-doris-connector;
sh build.sh
选择spark 版本和 scala版本后 等就是了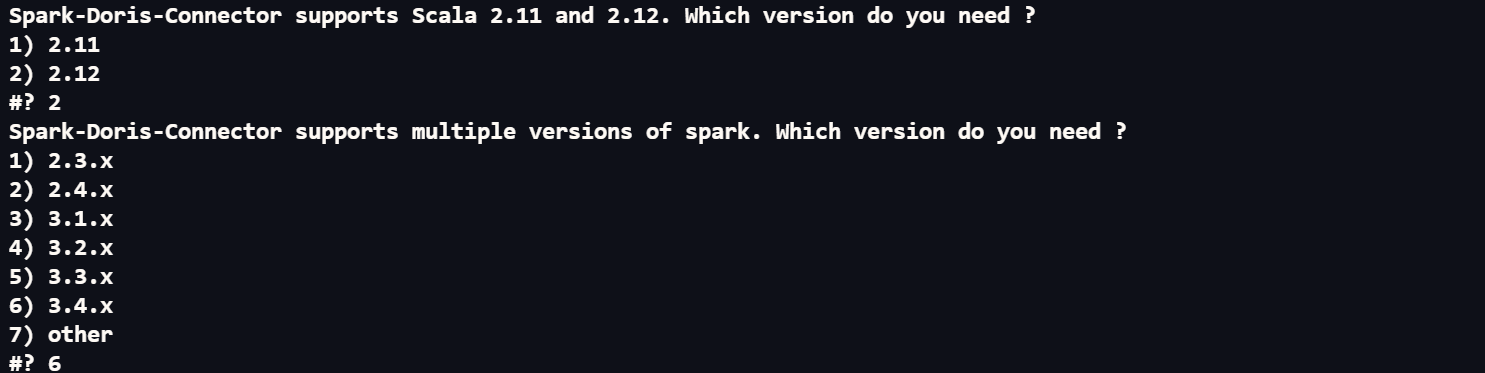
- build 后就是在源码下形成了一个依赖包,可以直接放入对应Spark 程序里面。如果要放到本地仓库,我的做法是执行对应的install 上传到本地,然后从挂载出来的仓库复制出来。
1 | cd /root/doris-branch-2.0/doris-spark-connector/spark-doris-connecto; |
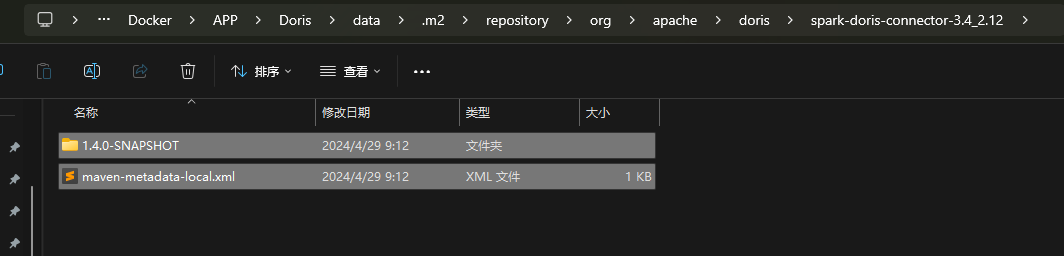
6. 最后就是修改工程pom版本到刚刚打包的版本。
1 | <properties> |
总结
其实思路就是传统的依赖包源码处理打包后,不是很难得方法,就是觉得官方提供编译环境的镜像的方法省了我不少时间。