开发AILLMXorbits Inference:模型推理框架
莫已诺
Xorbits Inference(Xinference)是一个性能强大且功能全面的分布式推理框架。可用于大语言模型(LLM),语音识别模型,多模态模型等各种模型的推理。通过 Xorbits Inference,你可以轻松地一键部署你自己的模型或内置的前沿开源模型。无论你是研究者,开发者,或是数据科学家,都可以通过 Xorbits Inference 与最前沿的 AI 模型,发掘更多可能。
主要功能
🌟 模型推理,轻而易举:大语言模型,语音识别模型,多模态模型的部署流程被大大简化。一个命令即可完成模型的部署工作。
⚡️ 前沿模型,应有尽有:框架内置众多中英文的前沿大语言模型,包括 baichuan,chatglm2 等,一键即可体验!内置模型列表还在快速更新中!
🖥 异构硬件,快如闪电:通过 ggml,同时使用你的 GPU 与 CPU 进行推理,降低延迟,提高吞吐!
⚙️ 接口调用,灵活多样:提供多种使用模型的接口,包括 OpenAI 兼容的 RESTful API(包括 Function Calling),RPC,命令行,web UI 等等。方便模型的管理与交互。
🌐 集群计算,分布协同: 支持分布式部署,通过内置的资源调度器,让不同大小的模型按需调度到不同机器,充分使用集群资源。
🔌 开放生态,无缝对接: 与流行的三方库无缝对接,包括 LangChain,LlamaIndex,Dify,以及 Chatbox。
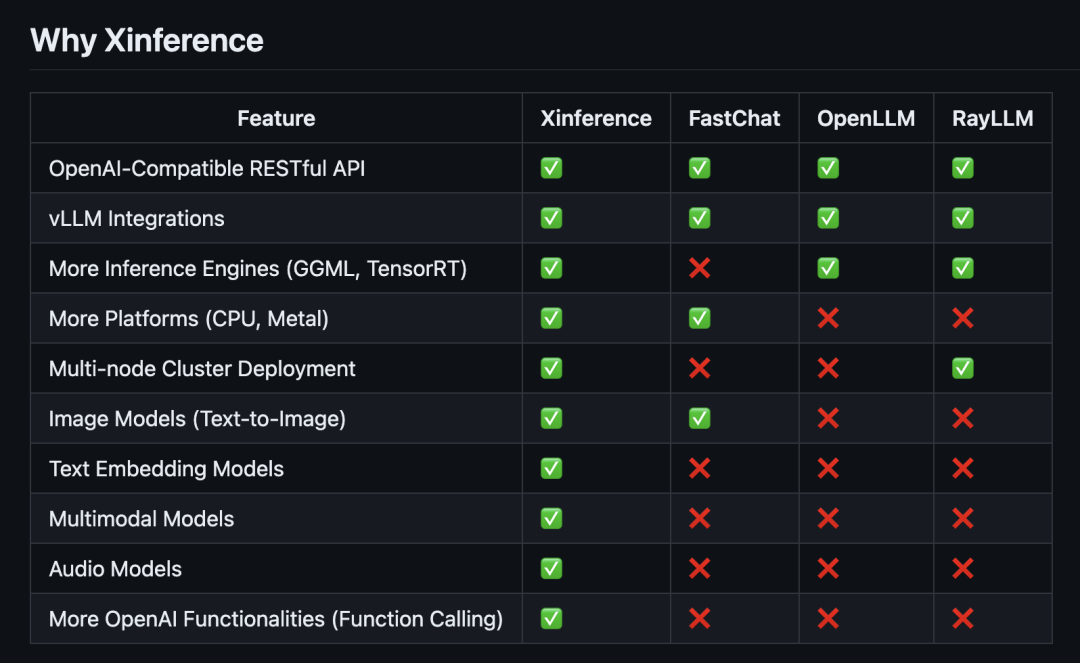
| 功能特点 |
Xinference |
FastChat |
OpenLLM |
RayLLM |
| 兼容 OpenAI 的 RESTful API |
✅ |
✅ |
✅ |
✅ |
| vLLM 集成 |
✅ |
✅ |
✅ |
✅ |
| 更多推理引擎(GGML、TensorRT) |
✅ |
❌ |
✅ |
✅ |
| 更多平台支持(CPU、Metal) |
✅ |
✅ |
❌ |
❌ |
| 分布式集群部署 |
✅ |
❌ |
❌ |
✅ |
| 图像模型(文生图) |
✅ |
✅ |
❌ |
❌ |
| 文本嵌入模型 |
✅ |
❌ |
❌ |
❌ |
| 多模态模型 |
✅ |
❌ |
❌ |
❌ |
| 语音识别模型 |
✅ |
❌ |
❌ |
❌ |
| 更多 OpenAI 功能 (函数调用) |
✅ |
❌ |
❌ |
❌ |
使用 pip 安装 Xinference,操作如下。(更多选项,请参阅安装页面。)
1
| pip install "xinference[all]"
|
Docker 部署
- 拉去镜像
docker pull xprobe/xinference:latest
- 导入镜像
docker load -i zfga-xf.tar
- 启动镜像
1
2
3
4
5
| docker run -d -v ./data/.xinference:/root/.xinference
-v ./data/.cache/huggingface:/root/.cache/huggingface
-v ./data/.cache/modelscope:/root/.cache/modelscope
-p 9997:9997 --name zfga-xf
--gpus "device=0" zfga_xf:0.1 xinference-local -H 0.0.0.0 --log-level debug
|
- 访问url 127.0.0.1:29997
- 注册模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| $ vim model_registrations.sh
# 添加以下内容。模型路径需要根据实际情况修改
curl 'http://127.0.0.1:29997/v1/model_registrations/LLM' \
-H 'Accept: */*' \
-H 'Accept-Language: zh-CN,zh;q=0.9,en;q=0.8' \
-H 'Connection: keep-alive' \
-H 'Content-Type: application/json' \
-H 'Cookie: token=no_auth' \
-H 'Origin: http://127.0.0.1:9997' \
-H 'Referer: http://127.0.0.1:9997/ui/' \
-H 'Sec-Fetch-Dest: empty' \
-H 'Sec-Fetch-Mode: cors' \
-H 'Sec-Fetch-Site: same-origin' \
-H 'User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36' \
-H 'sec-ch-ua: "Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-platform: "Linux"' \
--data-raw '{"model":"{\"version\":1,\"model_name\":\"autodl-tmp-glm-4-9b-chat\",\"model_description\":\"autodl-tmp-glm-4-9b-chat\",\"context_length\":2048,\"model_lang\":[\"en\",\"zh\"],\"model_ability\":[\"generate\",\"chat\"],\"model_family\":\"glm4-chat\",\"model_specs\":[{\"model_uri\":\"/root/autodl-tmp/glm-4-9b-chat\",\"model_size_in_billions\":9,\"model_format\":\"pytorch\",\"quantizations\":[\"none\"]}],\"prompt_style\":{\"style_name\":\"CHATGLM3\",\"system_prompt\":\"\",\"roles\":[\"user\",\"assistant\"],\"intra_message_sep\":\"\",\"inter_message_sep\":\"\",\"stop\":[\"<|endoftext|>\",\"<|user|>\",\"<|observation|>\"],\"stop_token_ids\":[151329,151336,151338]}}","persist":true}'
|
Docker 环境变量
XINFERENCE_ENDPOINT
Xinference 的服务地址,用来与 Xinference 连接。默认地址是 http://127.0.0.1:9997,可以在日志中获得这个地址。
XINFERENCE_MODEL_SRC
配置模型下载仓库。默认下载源是 “huggingface”,也可以设置为 “modelscope” 作为下载源。
XINFERENCE_HOME
Xinference 默认使用 <HOME>/.xinference 作为默认目录来存储模型以及日志等必要的文件。其中 <HOME> 是当前用户的主目录。可以通过配置这个环境变量来修改默认目录。
XINFERENCE_HEALTH_CHECK_ATTEMPTS
Xinference 启动时健康检查的次数,如果超过这个次数还未成功,启动会报错,默认值为 3。
XINFERENCE_HEALTH_CHECK_INTERVAL
Xinference 启动时健康检查的时间间隔,如果超过这个时间还未成功,启动会报错,默认值为 3。
XINFERENCE_DISABLE_HEALTH_CHECK
在满足条件时,Xinference 会自动汇报worker健康状况,设置改环境变量为 1可以禁用健康检查。
XINFERENCE_DISABLE_VLLM
在满足条件时,Xinference 会自动使用 vLLM 作为推理引擎提供推理效率,设置改环境变量为 1可以禁用 vLLM。
XINFERENCE_DISABLE_METRICS
Xinference 会默认在 supervisor 和 worker 上启用 metrics exporter。设置环境变量为 1可以在 supervisor 上禁用 /metrics 端点,并在 worker 上禁用 HTTP 服务(仅提供 /metrics 端点)
Xinference 加载本地模型:
关于 Xinference 加载本地模型: Xinference 内置模型会自动下载,如果想让它加载本机下载好的模型,可以在启动 Xinference 服务后,到项目 tools/model_loaders 目录下执行 streamlit run xinference_manager.py,按照页面提示为指定模型设置本地路径即可.
api 文档地址
http://127.0.0.1:9997/docs

api调用
python环境安装 xinference
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| from typing import List
from xinference.client import Client
from xinference.types import ChatCompletionMessage
if __name__ == "__main__":
endpoint = 'http://127.0.0.1:9997'
model_name = 'qwen2-instruct'
model_size_in_billions = '1_5'
model_format = 'pytorch'
quantization = None
model_engine = "transformers"
print(f"Xinference endpoint: {endpoint}")
print(f"Model Name: {model_name}")
print(f"Model Size (in billions): {model_size_in_billions}")
print(f"Model Format: {model_format}")
print(f"Quantization: {quantization}")
client = Client(endpoint)
model = client.get_model("qwen2-instruct")
chat_history: List["ChatCompletionMessage"] = []
while True:
prompt = input("you: ")
completion = model.chat(
prompt=prompt,
chat_history=chat_history,
generate_config={"max_tokens": 1024},
)
content = completion["choices"][0]["message"]["content"]
print(f"{model_name}: {content}")
chat_history.append(ChatCompletionMessage(role="user", content=prompt))
chat_history.append(ChatCompletionMessage(role="assistant", content=content))
|